iterator
序
春天来了,又到了。。。呃,填坑的季节

我们之前已经把简易的sql生成器做完了,现在还差最后一个部分,数据迭代器。
接下来我们就开始本次数据迭代器的编码,顺便发个声明:
本文所有操作均基于golang的database/sql包以及原生反射包支持
支撑函数
首先我们来聊一聊本次编码所需要的一些工具函数支撑
重置一个interface
func reset(data interface{}) error {
v := reflect.ValueOf(data).Elem()
t := v.Type()
var z reflect.Value
switch v.Kind() {
case reflect.Slice:
z = reflect.MakeSlice(t, 0, v.Cap())
default:
z = reflect.Zero(t)
}
v.Set(z)
return nil
}
单次迭代sql.Rows
//fetchResult 通过列名抓取响应属性生成一个类型指针
func fetchResult(rows *sql.Rows, itemT reflect.Type, columns []string) (reflect.Value, error) {
var err error
objT := reflect.New(itemT) //创建一个新的指针
values := make([]interface{}, len(columns)) //根据查询列名构建需要获取的field指针切片
fieldMap, _ := reflectx.StructMap(objT.Interface())//根据反射获取列名与具体field的映射
tmpMap := make(map[string]reflect.Value)//创建一个临时map 用于处理time的赋值
//根据查询列明循环
for i, k := range columns {
f, ok := fieldMap[k]//查找当前类型的field映射
if !ok {//不存在,加入占位interface
values[i] = new(interface{})
continue
}
values[i] = f.Addr().Interface()
if ok {
//识别如果是time类型特殊处理,并使用映射map来保存具体值
switch values[i].(type) {
case time.Time, *time.Time:
tmpValue := reflect.New(reflect.TypeOf(""))
values[i] = tmpValue.Interface()
tmpMap[k] = tmpValue
}
}
}
//调用scan函数
err = rows.Scan(values...)
if err == nil {
//遍历我们的time映射,赋值回具体的field
for k, v := range tmpMap {
curr := v.Elem().String()
t, _ := time.Parse("2006-01-02 15:04:05", curr)
currV := reflect.ValueOf(t)
fieldMap[k].Set(currV)
}
}
//返回当前obj
return objT, err
}
有了这两个函数,基本是满足了单条赋值与重置的功能。
下面加入几个error的定义
type IErr string
func (ie IErr) Error() string {
return string(ie)
}
const (
ErrNotPtr = IErr("Arg Must Be Ptr")
ErrNotSlice = IErr("Arg Must Be Slice")
ErrNoMoreRows = IErr("No More Rows")
)
这几个基本上就是在函数处理过程中,出现的几个可预见错误。
下面就开始我们今天的主题!

迭代器
先来声明一个struct和一个接口
type (
iterator struct {
cursor *sql.Rows
once sync.Once
err error
}
Iterator interface {
All(i interface{}) error
One(i interface{}) error
}
)
func (ite *iterator) close() {
ite.once.Do(func() {
if ite.cursor != nil {
ite.cursor.Close()
}
})
}
func New(rs *sql.Rows) *iterator {
return &iterator{rs, sync.Once{}, nil}
}
这里面定义了一个迭代器,顺便做了一个迭代器close函数,用来关闭他的cursor
接下来是All 函数的实现
func (ite *iterator) All(dst interface{}) error {
dstv := reflect.ValueOf(dst)
if dstv.IsNil() || dstv.Kind() != reflect.Ptr {
return ErrNotPtr
}
if dstv.Elem().Kind() != reflect.Slice {
return ErrNotSlice
}
defer ite.close()
rows := ite.cursor //获取当前cursor
slicev := dstv.Elem() //获取当前切片Value
itemT := slicev.Type().Elem() //获取切片的type
columns, err := rows.Columns() //获取查询列名
if err != nil {
return err
}
reset(dst)//重置
for rows.Next() { //迭代
//单个数据填装
item, err := fetchResult(rows, itemT, columns)
if err != nil {
return err
}
//切片数据加入
if itemT.Kind() == reflect.Ptr {
slicev = reflect.Append(slicev, item)
} else {
slicev = reflect.Append(slicev, reflect.Indirect(item))
}
}
//设置切片
dstv.Elem().Set(slicev)
//返回err
return rows.Err()
}
在然后是One函数的实现
func (ite *iterator) One(dst interface{}) error {
dstv := reflect.ValueOf(dst)
if dstv.IsNil() || dstv.Kind() != reflect.Ptr {
return ErrNotPtr
}
itemV := dstv.Elem()
reset(dst)
defer ite.close()
rows := ite.cursor
itemT := dstv.Type().Elem()
columns, err := rows.Columns()
if err != nil {
return err
}
if !rows.Next() {
return ErrNoMoreRows
}
//与all函数的最大区别就在于这里,是fetch了一条数据
item, err := fetchResult(rows, itemT, columns)
if err != nil {
return err
}
if itemT.Kind() == reflect.Ptr {
itemV.Set(item)
} else {
itemV.Set(reflect.Indirect(item))
}
return rows.Err()
}
至此,实现部分基本结束,我们开启测试用例的编写。

Test Case
首先,我们这次测试的是迭代器,那么要先创建一个数据表
create table borm_test
(
id int auto_increment
primary key,
t_string varchar(50) null,
t_bool tinyint(1) null,
t_time timestamp null
);
再搞进去几条数据
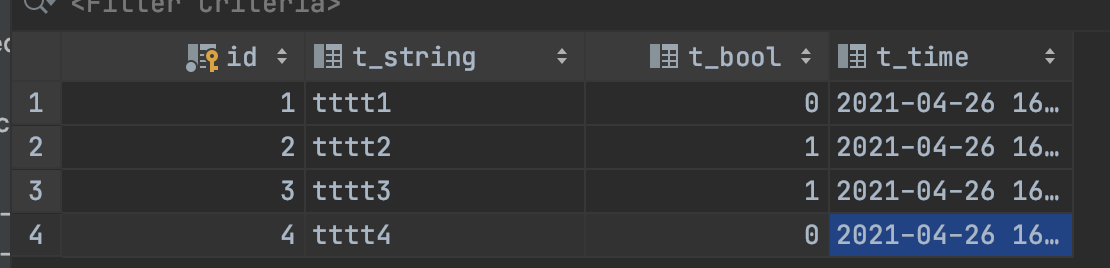
搞一个创建链接和格式化返回的函数
func open() *sql.DB {
dsn := "user:pwd@tcp(127.0.0.1:3306)/test?loc=Asia%2FShanghai&charset=utf8mb4"
db, err := sql.Open("mysql", dsn)
if err != nil {
panic(err)
}
return db
}
func fmtStr(i interface{}) string {
b, _ := json.MarshalIndent(i, "", " ")
return string(b)
}
借用selector来生成一个查询语句,然后看我们的All函数testCase
func TestIterator_All(t *testing.T) {
db := open()
defer db.Close()
selector := sqlbuilder.SelectFrom("borm_test").Limit(10)
rows, err := db.Query(selector.Sql(), selector.Args()...)
if err != nil {
t.Error(err.Error())
return
}
ite := New(rows)
res := make([]TestStruct, 0)
err = ite.All(&res)
if err != nil {
t.Error(err.Error())
return
}
t.Log(fmtStr(res))
}
testCase打印
=== RUN TestIterator_All
iter_test.go:50: [
{
"Id": 1,
"TString": "tttt1",
"TBool": false,
"TTime": "2021-04-26T16:41:02Z"
},
{
"Id": 2,
"TString": "tttt2",
"TBool": true,
"TTime": "2021-04-26T16:41:15Z"
},
{
"Id": 3,
"TString": "tttt3",
"TBool": true,
"TTime": "2021-04-26T16:41:23Z"
},
{
"Id": 4,
"TString": "tttt4",
"TBool": false,
"TTime": "2021-04-26T16:41:30Z"
}
]
--- PASS: TestIterator_All (0.01s)
PASS
接下来看我们的One函数testCase
func TestIterator_One(t *testing.T) {
db := open()
defer db.Close()
selector := sqlbuilder.SelectFrom("borm_test").Limit(1)
rows, err := db.Query(selector.Sql(), selector.Args()...)
if err != nil {
t.Error(err.Error())
return
}
ite := New(rows)
res := TestStruct{}
if err = ite.One(&res); err != nil {
t.Error(err.Error())
return
}
t.Log(fmtStr(res))
}
testCase打印
=== RUN TestIterator_One
iter_test.go:73: {
"Id": 1,
"TString": "tttt1",
"TBool": false,
"TTime": "2021-04-26T16:41:02Z"
}
--- PASS: TestIterator_One (0.01s)
PASS
简单的测试了一下几个常用的数据类型,目前看来是满足功能需要。
后记
迭代器部分基本上已经OK了,下一步,也就是最重要的一步,整合!
整合过后整个框架的功能也就行程了一个闭环。
当然,懒惰的我就不打算今天写了。。。。
所以,有人期待嘛?

