ORM浅谈
– 如何定制化一个自己的ORM
楔子
ORM框架 是我们开发过程中不可或缺的一环,无论是使用哪一种语言,都有相匹配的几款 ORM框架 供您挑选。
但在很多情况下,开源的 ORM框架 功能虽然强大,但是整体体积偏大,使用起来相对于沉重。并且有的有一些自定义的功能也不好集成进去。
怀着这样的目的,我就开始了我们定制化自己的 ORM框架 旅程…
本文基于个人博客的文章 《BORM系列》 进行整理归纳,文章涉及到的代码,全部使用Golang进行编写。
想看源码的小伙伴可以在 github 上观看,并欢迎提出各种方向的意见。
开始
设计
从整体看来,我想把一个 ORM框架 分为3个部分
-
SQL生成器
根据Map/Struct/Native 等方式生成sql
-
数据迭代器
将sql.Result进行迭代,封装后进行指针赋值
-
数据库特性及扩展
这部分相对就比较零散了,比如Tx等功能的支持,sql方言的处理,常用sql的工具封装,等等
准备工作 (Reflect)
再正式开始之前,有一个很重要的知识要提前准备一下。
像go这种静态强类型语言,想随心所欲的根据生成SQL,那么 反射(reflect) 的知识一定不能少。
先介绍一下本文用到的几个反射包函数与类型
//函数
reflect.ValueOf()//获取一个变量的值
reflect.TypeOf()//获取一个变量类型
//类型
reflect.Type//类型
reflect.Value//值
reflect.StructField//结构体成员变量
reflect.Tag//filed Tag
//结构体函数
Type.NumField()//获取成员变量的数量
Type.Field(i) //获取成员变量的类型,返回值为reflect.StructField
Value.Kind() //获取类型
Value.Elem() //当类型为指针的时候,用于获取具体值
准备工作 (SQL)
select语句因为存在聚合函数还有不同where条件组合等,并不太适合放在这里举例。
当然,在github已经上传的代码里,也有基于tag的where语句生成功能,有兴趣的小伙伴可以去看看。
这里我们准备拿简单的 Insert/Update 语句举例。
Insert
常见的insert语句大概有三种
-
按照列名插入
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...); -
提供全部数据插入
INSERT INTO table_name VALUES (value1,value2,value3,...); -
set插入
INSERT INTO table_name SET column1 = value1, column2 = value2, column3 = value3...;
不难看出,第二、第三中SQL 各有各的缺点,比如:
- 第二种SQL需要按顺序指定全部列的值
- 第三种SQL不能批量插入
所以我们的Insert语句生成 就采用第一种方式来进行。
Update
至于Update语句,基本上就采用了最常规的方式:
UPDATE
table_name
SET
column1 = value1,
column2 = value2,
column3 = value3...
WHERE
field = xxx;
SQL生成器
在go语言来讲,如果要根据结构体来生成一个Insert语句,大概是这个样子
INSERT INTO
{表名}
({Field1 对应Column},{Field2 对应Column},{Field2 对应Column}...)
VALUES
({Value1},{Value2},{Value3}...)
除了上述的反射相关代码,这里还需要用到Golang的一个特性 — 接口
我们使用接口来获取结构体对应表名,如果没有实现我们的接口,那么将采用结构体名字的蛇形命名转换
- 接口定义
type(
Table interface {
TableName() string
}
)
- 表名获取
var tName string
if t, ok := i.(Table); ok {
//如果实现了接口,直接采用定制表名
tName = t.TableName()
} else {
//未实现接口,取struct名称的蛇形
tName = stringx.SnakeName(reflectx.StructName(i))
}
如此一来,关于如何获取表名的问题就告一段落了,接下来我们要根据结构体成员变量来获取对应的Column名称
对于column名,我们这边同样也提供两个选项
- 使用 `db:column_name` 来指定名称
- 使用蛇形命名转换FieldName
- 同时支持忽略属性
- 列名获取
column := t.Tag.Get("db")
if len(column) == 0 {
//如无自定义column,取field名称的蛇形
column = stringx.SnakeName(t.Name)
}
// "-" 表示忽略,空数据 也直接跳过
if column == "-" || reflectx.IsNull(v) {
return nil
}
现在让我们整理一下,从我们拿到一个未知的结构体,到给他生成SQL 大体上是这么个流程
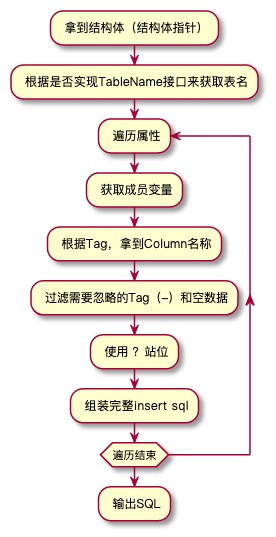
当然,为了提升性能,针对于同一个结构体,我们生成的sql可以缓存起来,不用再次调用反射,可以有效提升性能 ==(由于我这里加了空值识别,导致空值可能影响SQL的生成,不太适用这个缓存)==
对于Update语句来讲,表名获取,列名站位其实和Insert语句是一样的。
有个比较特殊的地方就是Where语句的部分
UPDATE
{表名}
SET
{Field1 对应Column} = value1,
{Field2 对应Column} = value2,
{Field3 对应Column} = value3...
WHERE
field = xxx;
这里咱们主要说一下,在Where语句这里是如何异想天开的。
关于Where语句的生成,常见的 Golang ORM框架 是这么设计的
- 自定义类型(type Cond Map[string]interface{}) – upper.io
- 链式调用 sqlBuilder.Where(“a > ?",a).Where(“b = ?",b) – upper.io/GORM
由于笔者是从 JAVA 转到 Golang 的开发。在 Struct1框架(Wiki,百科链接没有找到) 制霸 MVC 的时代,有个比较火的概念叫做模型驱动,所以这里我想把他设计成根据模型来进行简单的Where条件生成。
设计的目的是这样,根据传入的模型,来分析需要生成的Where条件,借用reflect.Tag 来进行参数传入与拼接。 ==(注意,这里的模型驱动,不适用复杂条件)==
首先要定义我们的模型,这里接住reflect.Tag来拿到相应的变量
const (
DbwTag = "dbw"
DbwGreaterThan = "gt"
DbwLessThan = "lt"
DbwEqual = "eq"
)
目前我们的Demo 采用 and 来链接模型中不同的条件,目前支持 =,>,< 三个运算符。
- 符号转换
func whereFlag(flag string) string {
switch flag {
case DbwEqual:
return "="
case DbwGreaterThan:
return ">"
case DbwLessThan:
return "<"
default:
panic("where flag " + flag + " not support")
}
}
- 自动where语句的生成
func whereSql(t reflect.StructField) string {
where := t.Tag.Get(DbwTag)
if len(where) == 0 {
return ""
}
column := ColumnName(t) //这里参考之前写的根据Field获取ColumnName
return fmt.Sprintf("%s %s ?", column, whereFlag(where))
}
这样就完成了一个Where语句的自动生成,下面看一下Where语句的生成流程:
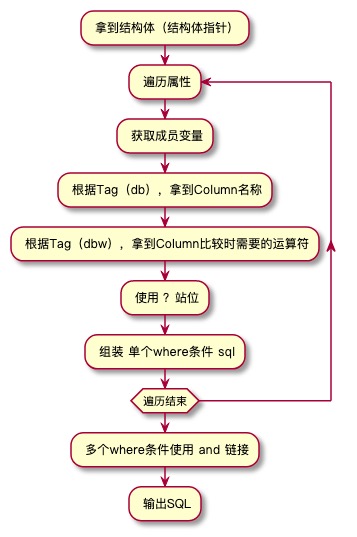
完成了Where部分的代码实现逻辑,再结合Insert时才用的表名获取、参数拼装,这样一个update语句的生成器就完成了。
我们常规工作中的 CRUD ,目前CU已经完成,D其实相当于U的一个变种(只有表名解析与Where语句生成),至于最复杂的R,SQL生成的部分相信已经难不倒大家了。关于读操作,还有很大的比重在数据迭代器部分,我们留在下一部分娓娓道来…
数据迭代器
数据迭代器部分主要依赖于Golang原生的 database/sql 包进行二次开发。
首先对于数据的迭代,我们要先获取本次查询结果返回的所有列
- 列名获取
var rows *sql.Rows //由db.QueryRows()返回
columns, err := rows.Columns() //获取查询列名
然后要获取目标切片指针对应切片中的类型 (这句话有点绕,可以理解为返回结果需要填充的结构体)
- 获取类型对应的结构
type Valuex struct {
reflect.Value
Tag reflect.StructTag
}
func StructMap(i interface{}) (res map[string]Valuex, err error) {
res = make(map[string]Valuex)
err = StructRange(i, func(t reflect.StructField, v reflect.Value) error {
res[ColumnName(t)] = Valuex{
Value: v,
Tag: t.Tag,
}
return nil
})
return
}
这样我们就有了一个 name => type 的映射,便于我们迭代时去寻找对应的属性。
接下来使用 rows.Next() 进行游标偏移,并开始获取查询到的数据。
- 单次的数据查找
//fetchResult 通过列名抓取响应属性生成一个类型指针
func fetchResult(rows *sql.Rows, itemT reflect.Type, columns []string) (reflect.Value, error) {
objT := reflect.New(itemT)
values := make([]interface{}, len(columns))
fieldMap, _ := reflectx.StructMap(objT.Interface())
for i, k := range columns {
f, ok := fieldMap[k]
if !ok {
values[i] = new(interface{})
continue
}
curr := f.Addr().Interface()
switch curr.(type) {
case time.Time, *time.Time:
format := defTimeFormat
if dbFmt := f.Tag.Get("fmt"); len(dbFmt) > 0 {
format = dbFmt
}
values[i] = NewTimeScanner(f.Value, format)
default:
values[i] = curr
}
}
return objT, rows.Scan(values...)
}
这里明显看到,对于时间参数,我们做了特殊处理,由于默认的time.Time 没有实现 database/sql 包的 Scanner 接口,导致结构体成员变量包含时间类型的时候比较难搞,这里我们手动给他实现一下。
- Scanner接口实现
type (
TimeScanner struct {
v reflect.Value
format string
}
)
const defTimeFormat = "2006-01-02 15:04:05"
func (t TimeScanner) Scan(src interface{}) (err error) {
var (
curr time.Time
)
switch src.(type) {
case []byte:
curr, err = time.Parse(t.format, string(src.([]byte)))
if err != nil {
return
}
case string:
curr, err = time.Parse(t.format, src.(string))
if err != nil {
return
}
case int64:
curr = time.Unix(src.(int64), 0)
case nil:
return
default:
return ErrTimeScan
}
currV := reflect.ValueOf(curr)
t.v.Set(currV)
return
}
func NewTimeScanner(v reflect.Value, format string) sql.Scanner {
return &TimeScanner{
v: v,
format: format,
}
}
由于基础包支持,其他基础类型包含 string 都可以直接在 Scan 函数的调用中传入指针作为变量。
好了,让我们来再次整理一下数据迭代器的整个流程:
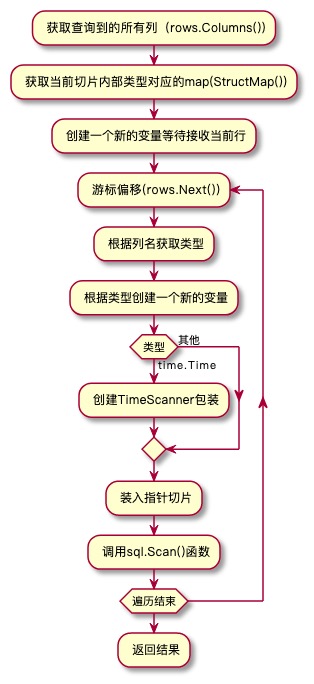
至此,关于迭代器相关的内容基本上就已经说完了。
更加详细的内容,有兴趣的小伙伴可以自行去 github 查看代码细节
数据库特性及扩展
关于特性与扩展这方面,其实更多的是我对于核心代码的包装。
这里举几个栗子
- 兼容sql.DB和sql.Tx的接口封装
type (
executor struct {
exec SqlExecutor
}
)
func (d *executor) Exec(sql string, args ...interface{}) (sql.Result, error) {
return d.exec.Exec(sql, args...)
}
func (d *executor) Query(sql string, args ...interface{}) (*sql.Rows, error) {
return d.exec.Query(sql, args...)
}
func (d *executor) QueryRow(sql string, args ...interface{}) *sql.Row {
return d.exec.QueryRow(sql, args...)
}
在封装的基础上,包装更多的工具函数
func (d *executor) Select(s ...string) Selector {
return NewSelector(d.exec, sqlbuilder.Select(s...))
}
func (d *executor) SelectFrom(s string) Selector {
return NewSelector(d.exec, sqlbuilder.SelectFrom(s))
}
func (d *executor) DeleteFrom(tableName string) Deleter {
return NewDeleter(d.exec, sqlbuilder.DeleteFrom(tableName))
}
func (d *executor) AutoInsert(t interface{}) (sql.Result, error) {
return NewInserter(d.exec, sqlbuilder.AutoInsert(t)).Exec()
}
func (d *executor) Count(i interface{}) (int64, error) {
var (
tb = sqlbuilder.TableName(i)
sb = sqlbuilder.Select("count(*) as c").From(tb)
tmp struct {
C int64
}
err error
)
err = NewSelector(d.exec, sb).AutoWhere(i).One(&tmp)
return tmp.C, err
}
func newExec(db SqlExecutor) *executor {
return &executor{exec: db}
}
这里也偷偷封装了一个自己常用的Count函数。
然后再对于MySQL进行一个友好的开箱支持~
type (
Connector interface {
DriverName() string
ConnStr() string
GetPoolSize() int
}
MySQLConfig struct {
User string `yaml:"user" json:"user" xml:"user"`
Pwd string `yaml:"pwd" json:"pwd" xml:"pwd"`
Db string `yaml:"db" json:"db" xml:"db"`
Host string `yaml:"host" json:"host" xml:"host"`
Port int `yaml:"port" json:"port" xml:"port"`
PoolSize int `yaml:"pool_size" json:"pool_size" xml:"pool_size"`
Charset string `yaml:"charset" json:"charset" xml:"charset"`
Loc string `yaml:"loc" json:"loc" xml:"loc"`
}
)
func (mc *MySQLConfig) DriverName() string {
return "mysql"
}
func (mc *MySQLConfig) ConnStr() string {
return fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?charset=%s&parseTime=true&loc=%s", mc.User, mc.Pwd, mc.Host, mc.defPort(), mc.Db, mc.defCharset(), mc.defLoc())
}
func (mc *MySQLConfig) defPort() int {
if mc.Port == 0 {
mc.Port = 3306
}
return mc.Port
}
func (mc *MySQLConfig) GetPoolSize() int {
if mc.PoolSize == 0 {
mc.PoolSize = 10
}
return mc.PoolSize
}
func (mc *MySQLConfig) defCharset() string {
if len(mc.Charset) == 0 {
mc.Charset = "utf8"
}
return mc.Charset
}
func (mc *MySQLConfig) defLoc() string {
if len(mc.Loc) == 0 {
mc.Loc = "Asia%2FShanghai"
}
return mc.Loc
}
func New(conn db.Connector) (db.DataBase, error) {
if reflectx.IsNull(conn) {
return nil, errors.New("nil connector")
}
db, err := db.NewDB(conn.DriverName(), conn.ConnStr())
if err == nil {
db.SetMaxOpenConns(conn.GetPoolSize())
}
return db, err
}
再来一个MySQL的示例
cfg := &borm.MySQLConfig{
User: "root",
Pwd: "123456",
Db: "test",
Host: "127.0.0.1",
}
db, err := borm.New(cfg)
if err != nil {
panic(err)
}
后记
关于 ORM 的整合,基本上就在这里了。
拖拖拉拉写了好久,这一个系列搞完,对于个人提升还是蛮大的。
尤其对于 Golang 的 reflect 包使用,database/sql 包的使用,还有一些go语言设计上的认知,都有明显的提升。
写文章的过程,有利于深入挖掘自己所用过的东西,也在于总结归纳自己接触过的知识。
再次感谢各位有耐心看完,也欢迎各位大神拍砖。
最后,希望写代码的路上,有你有我大家都不孤单~
